Task 10 - Overview of Automation Pipelines
So far in this lab, you have done everything manually — editing YAML files in your code editor, running nac-validate from the terminal, executing terraform plan and terraform apply by hand, and verifying results in the Meraki Dashboard. Every step required you to remember the right command, run it in the correct order, and visually inspect the output before moving on. This works fine for learning and small-scale changes, but in a production environment with multiple engineers, frequent changes, and dozens of networks, this manual approach quickly becomes error-prone and difficult to scale. A missed validation step, a forgotten test, or an out-of-order deployment can lead to configuration drift or outages. This is where automation pipelines come in — they take the exact same steps you have been performing manually and execute them automatically, consistently, and repeatably every time a change is committed to your Git repository.
Automation pipelines are a set of automated processes that allow you to build, test, and deploy your code in a consistent and repeatable manner. They are essential for ensuring that your code is always in a deployable state and that any changes made to the code are thoroughly tested before being deployed to production.
We hear this in the context of software development, which isn’t what you are normally used to discussing with network operations. Yet many of these concepts are applicable to network operations as well. In the context of Network as Code with Meraki Dashboard, we utilize the underlying toolbase to automate the deployment of configuration. Yet the important element is that network changes are integrated into this software pipeline such that changes are integrated with validation and other software practices.
What is an Automation Pipeline?
Section titled “What is an Automation Pipeline?”An automation pipeline is a series of automated steps that take your code from development to production. It typically includes the following stages:
- Source Control: The code is stored in a version control system (VCS) such as Git. This allows for tracking changes, collaboration, and rollback if necessary.
- Build: The code is built into a deployable artifact. This can include compiling code, packaging files, and preparing the environment for deployment.
- Test: Automated tests are run to ensure that the code is functioning as expected. This can include unit tests, integration tests, and end-to-end tests.
- Deploy: The code is deployed to the target environment, such as a production server or a network device.
We can make the connection between these high level software concepts and network operations by looking at the following table:
| Stage | Software Development | Network Operations Equivalent |
|---|---|---|
| Source Control | Utilized to manage all code. Provides version control and tracking. | Utilized to manage all configuration. Provides version control and tracking. |
| Build | Compiles code, packages files, prepares environment. | Prepares configuration files, templates, and scripts for deployment. |
| Test | Runs automated tests to ensure code functions as expected. | Validates configuration and operational states before and after changes. |
| Deploy | Deploys code to target environment. | Deploys configuration to network devices via Meraki Dashboard. |
When you observe this in the context of software development, developers commit code into branches that are processed via software linting and other tools to ensure the code matches expected standards. Once peer review approves the code this is then moved to control branches like develop for further testing and integration. Finally code is then merged, compiled and tested to established standards.
The advantage of this for network configuration changes is the ability to integrate what we have mentioned before: Semantic validation, pre and post testing, and automated deployment. Network engineers simply codify intended state and the software pipeline is executed transparently to ensure all the required steps are completed to push the configuration correctly to the network.
Pipelines and Meraki as Code
Section titled “Pipelines and Meraki as Code”For Meraki as Code, we have following stages to complete the deployment flow:
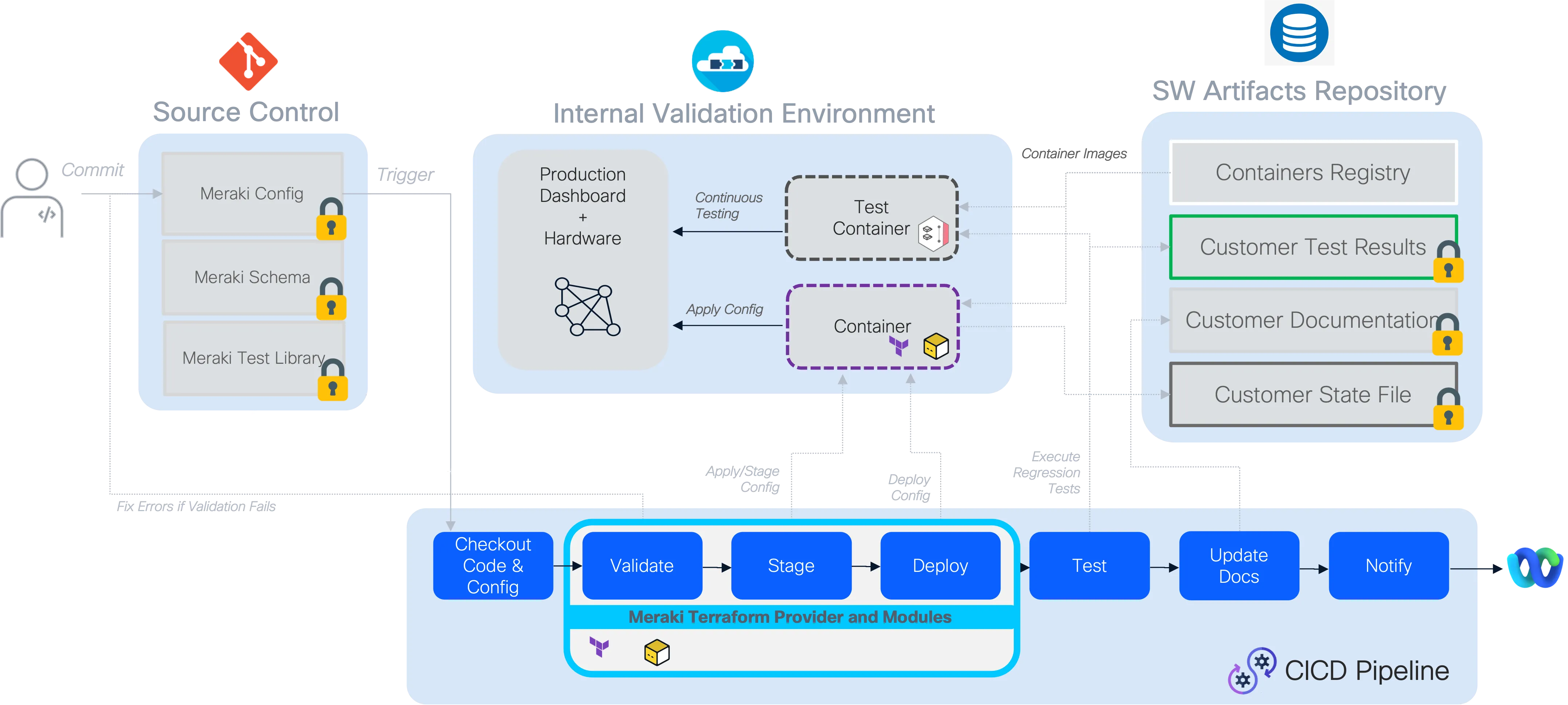
Complete Pipeline Flow Overview:
Preparation - Template Rendering Stage
Section titled “Preparation - Template Rendering Stage”During this stage, the templates (if used) are merged with the variables supplied for the network environment (including environment variables when used), creating one single, unified data model in memory for processing.
Validation Stage (pre-change validation)
Section titled “Validation Stage (pre-change validation)”During the validation stage, it is ensured that only valid configurations proceed to deployment. This stage uses nac-validate which we have already seen in previous sections.
What happens during validation:
Schema Compliance: The data model is validated against the predefined schema to ensure all required fields are present and data types are correct. This includes checking for mandatory fields like switch serial numbers and proper IP address formats.
Semantic Validation: Beyond basic schema compliance, the validation includes semantic checks that ensure the configuration makes logical sense from a networking perspective. This might include verifying that VLAN ranges don’t overlap, IP subnets are properly configured.
Custom Rules Engine: The validation stage can incorporate custom rules that enforce network-specific policies. These rules are written in Python and can range from simple naming convention enforcement to complex interconnectivity validation that prevents common configuration mistakes. These rules are available as part of the Services as Code service offering.
Validation Strategy: We can implement validation across different Git branching strategies to provide early feedback to network engineers. When a network operator commits changes to a feature branch, the pipeline automatically runs validation-only jobs, allowing for rapid iteration and error correction before the changes are merged into the main branch. In this lab, the branching is not implemented.
Benefits of Early Validation:
- Fast Feedback Loop: Engineers receive immediate feedback on their changes without waiting for full deployment cycles
- Reduced Risk: Invalid configurations are caught before they can impact the network
- Collaborative Development: Multiple engineers can work on different aspects of the network configuration with confidence that their changes will be validated consistently
Planning Stage
Section titled “Planning Stage”In this stage, Terraform generates an execution plan showing what changes it will make to reach the desired infrastructure state without actually applying them.
Deployment Stage
Section titled “Deployment Stage”The deployment stage transforms validated configuration data into actual network state through terraform provider. This stage represents the critical transition from intent (as expressed in the data model) to reality (as configured on network devices via Meraki Dashboard).
Testing Stage (post-deployment testing)
Section titled “Testing Stage (post-deployment testing)”The testing stage provides critical verification that the deployed configuration matches the intended state and that the network is functioning as expected. This stage uses the nac-test tool (previously known as iac-test) to perform comprehensive post-deployment validation.
Note: The current testing capabilities focus primarily on configuration accuracy validation. The testing ensures what was deployed matches the intended configuration defined in the data model.
What Testing Validates:
- Configuration Accuracy: Verifies that the configuration deployed to Meraki Dashboard exactly matches what was defined in the data model. The testing stage checks for discrepancies between the intended configuration and the actual state on the devices.
Testing Process:
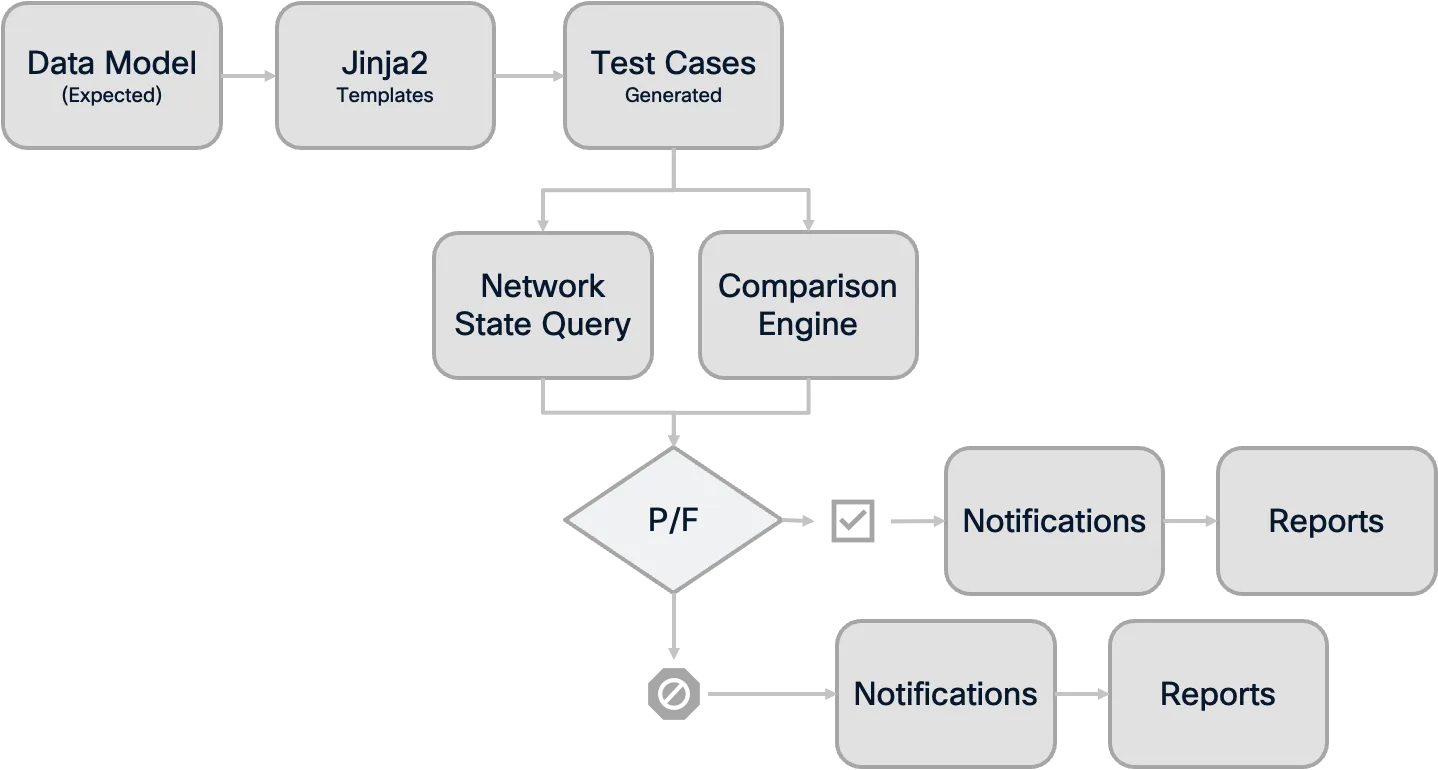
Template-Based Testing: The
nac-testtool uses Jinja2 templates that define the expected state based on the data model. These templates generate specific test cases that are executed against the actual network state.Human-Readable Output: Test results are generated in HTML report format for easy human review and analysis.
Comprehensive Reporting: Failed tests provide detailed information about what was expected versus what was found, making troubleshooting efficient and precise.
Testing Process Overview:
Integration with Pipeline:
- Artifact Collection: All test results are stored as pipeline artifacts, providing a permanent record of network state validation
- Failure Handling: Test failures provide immediate feedback on deployment issues and can trigger alerts to notify about the configuration discrepancies
- Change Documentation: Test reports serve as evidence for change documentation and operational processes
Benefits of Automated Testing:
- Confidence in Changes: Engineers can be confident that deployed changes work as intended
- Rapid Issue Detection: Problems are identified immediately after deployment, not during business hours when users report issues
- Documentation: Test results provide clear documentation of what was tested and aid in the troubleshooting process
Notification Stage (optional enhancement)
Section titled “Notification Stage (optional enhancement)”Notifications can also be configured as a final pipeline stage that provides stakeholders with real-time updates about deployment status and results. This stage can send deployment summaries to collaboration platforms like Cisco Webex Teams, Microsoft Teams, automatically distribute test reports and deployment artifacts to relevant stakeholders, and trigger alerts to on-call teams when critical deployments fail. Common integrations include sending adaptive cards with pipeline summaries, distributing comprehensive reports via email, or automatically creating ServiceNow change records with deployment results. This ensures that network operations teams stay informed about infrastructure changes without actively monitoring the pipeline interface.
Pipeline Benefits and Best Practices
Section titled “Pipeline Benefits and Best Practices”Implementing automation pipelines for Network as Code with Meraki Dashboard provides significant advantages over traditional network change management approaches:
Key Benefits
Section titled “Key Benefits”Risk Reduction: Every change is validated multiple times - first against schema and rules, then through deployment testing. This multi-layered approach dramatically reduces the risk of network outages or misconfigurations.
Consistency: All network changes follow the same standardized process, eliminating the variability that comes from manual processes or individual engineer preferences.
Auditability: Every change is tracked in version control, with complete visibility into who made what changes, when they were made, and what testing was performed.
Scalability: As network complexity grows, the pipeline approach scales much better than manual processes, allowing teams to manage larger and more complex network infrastructures.
Traditional vs Pipeline Approach Comparison:
| Traditional Manual Process | Automated Pipeline Process |
|---|---|
| 👤 Manual Configuration | 🤖 Automated Validation |
| ❌ Human Error Prone | ✅ Consistent & Reliable |
| 📝 Manual Documentation | 📊 Automatic Audit Trail |
| 🐌 Slow & Sequential | ⚡ Fast & Parallel |
| 🔍 Limited Testing | 🧪 Comprehensive Testing |
GitLab Terraform Pipeline Documentation
Section titled “GitLab Terraform Pipeline Documentation”Example: Step-by-Step CI/CD Pipeline for Meraki as Code
This pipeline automates the preparation, validation, planning, deployment, and testing of Terraform-based network configurations.
Pipeline Overview Table
Section titled “Pipeline Overview Table”| Stage | Purpose | Key Points |
|---|---|---|
| prepare | Render templates into a merged configuration file. | Skips if no template variables file; saves merged config as artifact. |
| validate | Check Terraform formatting and validate NAC configuration using nac-validate. | Validates data files and merged config with schema and custom rules. |
| plan | Generate Terraform execution plan and convert it to JSON for GitLab reporting. | Shows resource changes; posts summary as MR comment. |
| deploy | Apply the planned Terraform changes to the environment. | Main branch only; uses plan.tfplan from plan stage. |
| test-integration | Run automated integration tests on the deployed configuration with nac-test. | Tests both data files and merged config; HTML and JUnit reports. |
| test-idempotency | Ensure Terraform configuration is idempotent (no unexpected changes on reapply). | Fails if terraform plan detects drift after deployment. |
| notify | Send pipeline status notifications to Webex Teams. | Separate jobs for success and failure notifications. |
Let’s walk through the pipeline configuration used in this lab:
Docker Image
Section titled “Docker Image”image: danischm/nac:0.1.6Purpose: Specifies the Docker image used for all jobs in the pipeline. This image includes Terraform, Python, and nac-test for consistent execution. This image is built for labs and should not be used in production.
Variables
Section titled “Variables”variables: GIT_SSL_NO_VERIFY: 'true' SSL_CERT_DIR: /etc/gitlab-runner/ssl GIT_TEMPLATE_DIR: '/tmp/git-template-$CI_JOB_ID' GIT_STRATEGY: clone GITLAB_TOKEN: description: 'User Access Token. Used to create comments on Merge Requests' TF_HTTP_USERNAME: value: 'gitlab-ci-token' TF_HTTP_PASSWORD: value: '${CI_JOB_TOKEN}' WEBEX_ROOM_ID: '' WEBEX_TOKEN: '' GITLAB_API_URL: value: '${CI_API_V4_URL}' TF_HTTP_ADDRESS: value: '${GITLAB_API_URL}/projects/${CI_PROJECT_ID}/terraform/state/tfstate' TF_HTTP_LOCK_ADDRESS: value: ${TF_HTTP_ADDRESS}/lock TF_HTTP_LOCK_METHOD: 'POST' TF_HTTP_UNLOCK_ADDRESS: value: ${TF_HTTP_ADDRESS}/lock TF_HTTP_UNLOCK_METHOD: 'DELETE'Purpose: Declares credentials, tokens, and HTTP endpoints for Terraform state management, Webex notifications, and GitLab integration. The TF_HTTP_* variables configure the Terraform HTTP backend so that state is stored in GitLab rather than locally on the runner. GIT_SSL_NO_VERIFY is set to true for lab environments with self-signed certificates.
Stages
Section titled “Stages”stages: - prepare - validate - plan - deploy - test-integration - test-idempotency - notifyPurpose: Defines the pipeline execution order. After deployment, two separate test stages run: integration testing verifies the deployed configuration matches intent, while idempotency testing confirms that re-applying the same plan produces no changes. An optional notify stage sends results to collaboration tools like Webex.
Prepare Stage
Section titled “Prepare Stage”prepare: stage: prepare variables: DATA_DIR: 'data/' WORKSPACES_DIR: 'workspaces/' BRANCH_VARIABLES_FILE: 'data/08_branch_variables.nac.yaml' MERGED_CONFIG_FILE: 'workspaces/merged_configuration.nac.yaml' rules: - if: $CI_MERGE_REQUEST_ID - if: $CI_COMMIT_BRANCH == "main" script: - | if [ ! -f "${BRANCH_VARIABLES_FILE}" ]; then echo "branch_variables file not found. Skipping prepare stage." exit 0 fi - terraform -chdir="${WORKSPACES_DIR}" init || { echo "terraform init failed."; exit 1; } - terraform -chdir="${WORKSPACES_DIR}" apply -auto-approve || { echo "terraform apply failed."; exit 1; } - | if [ ! -f "${MERGED_CONFIG_FILE}" ]; then echo "merged_configuration.nac.yaml not found!" exit 1 else echo "merged_configuration.nac.yaml created successfully." fi artifacts: paths: - ${MERGED_CONFIG_FILE} when: always expire_in: 1 weekPurpose: Renders templates into a single merged configuration file. The workspaces/ directory contains a separate Terraform configuration that merges template files with variable files to produce merged_configuration.nac.yaml. If no branch variables file exists (meaning templates are not being used), the stage exits early. This stage runs on both merge requests and the main branch, so validation can happen before merging.
Validate Stage
Section titled “Validate Stage”validate: stage: validate needs: [prepare] variables: DATA_DIR: 'data' WORKSPACES_DIR: './workspaces' MERGED_CONFIG_FILE: './workspaces/merged_configuration.nac.yaml' rules: - if: $CI_MERGE_REQUEST_ID - if: $CI_COMMIT_BRANCH == "main" script: - echo "Checking Terraform formatting..." - terraform fmt -check | tee fmt_output.txt - | if grep -qE '\.tf' fmt_output.txt; then echo "One or more Terraform files are not formatted correctly." exit 1 else echo "All Terraform files are properly formatted." fi - echo "Checking for NAC YAML files..." - | NAC_FILES="" DATA_NAC_FILES=$(find "${DATA_DIR}" -type f -name "*.nac.yaml" \ ! -name "08_*.nac.yaml" \ ! -name "07_*.nac.yaml" 2>/dev/null) if [ -n "${DATA_NAC_FILES}" ]; then NAC_FILES="${NAC_FILES} ${DATA_NAC_FILES}" fi if [ -f "${MERGED_CONFIG_FILE}" ]; then NAC_FILES="${NAC_FILES} ${MERGED_CONFIG_FILE}" fi NAC_FILES=$(echo "${NAC_FILES}" | xargs) if [ -z "${NAC_FILES}" ]; then echo "No .nac.yaml files found (after exclusions). Skipping nac-validate." echo "SKIPPED: No .nac.yaml files found" > validate_output.txt else echo "Validating NAC YAML files:" printf ' %s\n' ${NAC_FILES} nac-validate ${NAC_FILES} -s schema.yaml -r rules/ --non-strict | tee validate_output.txt if grep -q "ERROR" validate_output.txt; then exit 1 fi fi artifacts: paths: - fmt_output.txt - validate_output.txt when: alwaysPurpose: Performs two checks before planning. First, it verifies Terraform files are properly formatted using terraform fmt -check. Second, it discovers all .nac.yaml files in the data/ directory (excluding template-related files prefixed with 07_* and 08_*) and the rendered merged_configuration.nac.yaml, then validates them with nac-validate against the schema and custom rules. The --non-strict flag allows validation to proceed even if optional fields are missing.
Plan Stage
Section titled “Plan Stage”plan: stage: plan needs: [validate] rules: - if: $CI_MERGE_REQUEST_ID - if: $CI_COMMIT_BRANCH == "main" resource_group: meraki script: - rm -rf .terraform/modules - terraform get -update - terraform init -input=false - terraform plan -out=plan.tfplan -input=false - terraform show -no-color plan.tfplan > plan.txt - terraform show -json plan.tfplan | jq > plan.json - terraform show -json plan.tfplan | jq '([.resource_changes[]?.change.actions?]|flatten)|{...}' > plan_gitlab.json - cat .terraform/modules/modules.json | jq '[.Modules[] | {Key, Source, Version}]' > modules.json - python3 .ci/gitlab-comment.py artifacts: paths: - plan.json - plan.txt - plan.tfplan - plan_gitlab.json - modules.json reports: terraform: plan_gitlab.jsonPurpose: Generates the Terraform execution plan and prepares reports for GitLab. The resource_group: meraki ensures only one plan/deploy cycle runs at a time, preventing concurrent changes to the same Meraki organization. The plan is exported in multiple formats: human-readable text (plan.txt), full JSON (plan.json), and a summary JSON (plan_gitlab.json) that GitLab uses to display resource change counts directly in the merge request UI. A Python script (gitlab-comment.py) posts a plan summary as a comment on the merge request.
Deploy Stage
Section titled “Deploy Stage”deploy: stage: deploy needs: [plan] resource_group: meraki rules: - if: $CI_COMMIT_BRANCH == "main" script: - terraform init -input=false - terraform apply -input=false -auto-approve plan.tfplan - terraform show -no-color plan.tfplan > plan.txt artifacts: paths: - defaults.yaml - plan.tfplan - plan.txtPurpose: Applies the Terraform plan to the Meraki Dashboard. This stage only runs on the main branch — merge requests stop after the plan stage, giving reviewers a chance to inspect the proposed changes before they are applied. The plan.tfplan artifact from the plan stage is used directly, ensuring that exactly what was reviewed gets deployed.
Test Integration Stage
Section titled “Test Integration Stage”test-integration: stage: test-integration needs: [deploy, prepare] variables: DATA_DIR: 'data' WORKSPACES_DIR: 'workspaces' rules: - if: $CI_COMMIT_BRANCH == "main" script: - | set -o pipefail TESTS_RAN=0
# Test data/ directory (excluding template-related files) if [ -d "${DATA_DIR}" ]; then DATA_FILES=$(find "${DATA_DIR}" -maxdepth 1 -type f -name "*.nac.yaml" \ ! -name "07_*.nac.yaml" ! -name "08_*.nac.yaml" 2>/dev/null) if [ -n "$DATA_FILES" ]; then nac-test -d "${DATA_DIR}" -t ./tests/templates -o ./tests/results \ --exclude "07_*.nac.yaml" --exclude "08_*.nac.yaml" |& tee test_output_data.txt if grep -q "ERROR" test_output_data.txt; then exit 1; fi TESTS_RAN=1 fi fi
# Test rendered merged configuration MERGED_DIR="${WORKSPACES_DIR}" if [ -d "${MERGED_DIR}" ]; then MERGED_FILES=$(find "${MERGED_DIR}" -maxdepth 1 -type f -name "*.nac.yaml" 2>/dev/null) if [ -n "$MERGED_FILES" ]; then nac-test -d "${MERGED_DIR}" -t ./tests/templates \ -o ./tests/results_merged |& tee test_output_merged.txt if grep -q "ERROR" test_output_merged.txt; then exit 1; fi TESTS_RAN=1 fi fi
if [ "$TESTS_RAN" -eq 0 ]; then echo "SKIPPED: No eligible .nac.yaml files found" > test_output.txt else echo "All nac-test runs completed successfully." fi artifacts: paths: - tests/results/*.html - tests/results/xunit.xml - tests/results_merged/*.html - tests/results_merged/xunit.xml - test_output*.txt reports: junit: - tests/results/xunit.xml - tests/results_merged/xunit.xmlPurpose: Runs post-deployment integration tests using nac-test. The stage tests two sets of configuration independently: the regular data model files in data/ (excluding template-related files prefixed with 07_* and 08_*) and the rendered merged configuration in workspaces/. The needs: [deploy, prepare] ensures the stage has access to both the deployed state and the rendered configuration artifact. Test results are stored as both HTML reports for human review and JUnit XML for GitLab’s built-in test reporting UI.
Test Idempotency Stage
Section titled “Test Idempotency Stage”test-idempotency: stage: test-idempotency needs: [deploy, test-integration] resource_group: meraki rules: - if: $CI_COMMIT_BRANCH == "main" script: - terraform init -input=false - | set +e terraform plan -input=false -out=idempotency.tfplan -detailed-exitcode exit_code=$? set -e
terraform show -no-color idempotency.tfplan > idempotency_plan.txt terraform show -json idempotency.tfplan | jq '.' > idempotency_plan.json
if [ "$exit_code" -eq 2 ]; then echo "Idempotency test failed — changes detected!" exit 1 elif [ "$exit_code" -eq 0 ]; then echo "Idempotent, no changes detected." else echo "Terraform plan failed with exit code $exit_code" exit $exit_code fi artifacts: paths: - idempotency_plan.txt - idempotency.tfplanPurpose: Confirms that the configuration is idempotent — re-running terraform plan after deployment should detect zero changes. The --detailed-exitcode flag makes Terraform return exit code 2 if changes are detected, which the script treats as a failure. This catches cases where the Meraki API normalizes values differently than what was specified, or where provider behavior causes unintended drift. A passing idempotency test gives confidence that the deployment is stable and complete.
Notify Stage
Section titled “Notify Stage”failure: stage: notify script: - python3 .ci/webex-notification-gitlab.py -f when: on_failure cache: []
success: stage: notify script: - python3 .ci/webex-notification-gitlab.py -s when: on_success cache: []Purpose: Sends pipeline status notifications to a Webex Teams room. The failure job runs only when the pipeline fails, and the success job runs only when all stages pass. This keeps the team informed of deployment outcomes without requiring them to monitor the GitLab UI directly. The Webex room ID and token are configured via the CI/CD variables defined earlier.
Summary
Section titled “Summary”Automation pipelines represent a fundamental shift in how network changes are managed, bringing the reliability and consistency of software development practices to network operations. By implementing the multi-stage pipeline approach (prepare, validate, plan, deploy, test, notify), organizations can significantly reduce the risk of network outages while improving the speed and consistency of network changes.
The combination of schema validation, automated deployment through Terraform, and post-deployment testing creates a robust framework that ensures network configurations are both syntactically correct and operationally sound. This foundation prepares network engineering teams to embrace Infrastructure as Code practices while maintaining the reliability and security that network operations demand.
In the next section, we will implement a working automation pipeline for Meraki as Code, putting these concepts into practice with hands-on configuration and deployment.